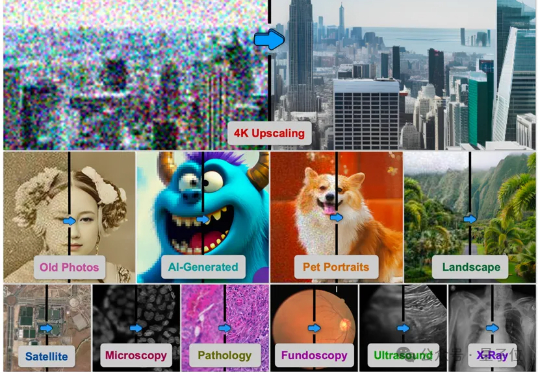
4K超分Agent修图师来了!一键救活所有模糊照片
4K超分Agent修图师来了!一键救活所有模糊照片由德克萨斯A&M大学、斯坦福大学、Snap公司、CU Boulder大学、德克萨斯大学奥斯汀分校、加州理工大学、Topaz Labs以及加州大学Merced分校的研究者联合提出的基于AI智能体的方法4KAgent针对不同类型的图像以及需求对图像进行智能修复并放大到4K分辨率,带来优秀的视觉感知效果。该工作已被NeurIPS 2025接收。
来自主题: AI技术研报
8971 点击 2025-11-21 17:03